
Leader election in rust the journey towards implementing nun-db leader election
I started Nun-db to be a real-time database of one product I was building. One of the goals for that product was never to be down.
Running my own SaS company for over ten years and been an Engineer and Cloud/SRE consultant for the last six years has taught me that resilience and not requiring manual intervention upon failure can save a person or team night sleep or holiday, so of course, I value no downtime at my heart. Moreover, I want to make Nun-db independent from manual intervention, and resilience was not negotiable.
How do you ensure you are never down? You run in the multi-region, multi-cloud providers, you run distributed, so if GCP is down, the system can still work from AWS or Azure, or Linode. That is why I discarded solutions like Firebase right away. First of all, I would like it to be open-source. Second I would like to make it close to unbreakable. We used Firebase in the startup I worked. Our single point of failure and the only non-open source component made our resilience much harder and the proper multi-cloud deployment impossible.
Once I start reading about distributed databases, leader election shows up time after time. The active-active and muti-leader database algorithms are hard to implement (and sometimes slower). They sometimes require complicated APIs for the end-users(applications) to deal with conflicts and so on. Simplicity is just another great value to me as much as resilience, so we decided to move on with a single leader model, at least for a start. But then How I determine who the leader is? The answer to that is an election.
Why do we need a leader in the first place?
Have you ever asked yourself that? Why databases need a primary, master, or leader? So here is a nonspecialist opinion.
Building consensus is hard
Consensus means agreeing into some state, in this case, like, for example, the value for a key, let’s see a simple example.
- Client A writes to node X the value
state=1. - Client A writes to node Y the value
state=2at the same time…
What value will be kept, and what value will be ignored?
As these commands run in different nodes, they can run at the time even if you lock the value while operating it.
A straightforward solution is not to let that happen by driving all writes to a single node on your cluster. The next question here may be to what node? The leader.
Note: There are lots of good strategies for muti-leader (cockroach DB implement it, for example) or active-active replication, and I may want to implement some of them in the future in Nun-db, in this case, so I may write about that soon, so each tiny client for Nun-db will work as a sub replica of the primary database, and there will be a high-level way to solve conflicts (but this is subject for another post)
For now, a single leader works fine and facilitates a lot of the implementation. However, my best reference book recommends not to implement election because it is complicated and error-prone. Instead, it recommends using ZooKeeper, but I would like to keep Nun-db deployment as simple as possible, so I took it as a challenge to make it work. For the rest of this article, I will show how I implemented the election without an external coordinator and how it worked.
When to run an election?
Leaders are important, and elections are problematic while running (just like in real life), so you want to avoid it as much as possible.
- Nun-db only runs election when the leader dies (is election a good name for this?) or when a leader steps down on propose (to update, for example).
- If a replica set is added to the cluster is always starts as secondary.
- The older replica running wins the election.
Choosing an algorithm
Here is where the fun started. I start to read about promising alternatives. Next, I will present them and what parts of each I incorporated in Nun-db’s implementation.
Raft
Raft kept showing out as an alternative, and seems to be widely used, it implements a voting system and a ping to re-run an election if the leader stops responding, big databases implement Raft as its election and replication model, but the protocol is not the simplest, I would like to have a robust yet simple and fast maybe even deterministic election algorithm. Therefore I decided not to move on with Raft. On the other hand, I liked the ping part of the protocol. In case the leader does not die but for some reason became unresponsive, would feature to react to that and elect a new leader to take over; I think it would be a good fit for Nun-db’s core values.
I plan to add it as a future step in this distributed features rollout. By the time I am writing this post, the Nun-db’s central deployment cluster has been running as a multi-machine deployment. I want to run that code in production under real load and see how it will behave before shipping more distributed features o this part of the code.
Efficient leader election in complete networks
One of the first papers I read was this. I liked the overall idea of the paper, but having to have a complete network was not a great idea for me. I ended up having to have to implement the complete network either way, but I found simpler alternatives.
Leader Election in Distributed System with Crash Failures
Crash Failures are essential to Nun-db. If you ever run any production load in a distributed database, you will most likely agree with me that all databases need it. I wanted to pick the most straightforward alternative the could meet the requirements I had. With that in mind, I choose the “Bully algorithm” to move on.
The Bully algorithm
My understanding of the bully algorithm was:
When an election is run
A node sends a new Election message.
If it receives a message with a higher id than it has, it set itself as secondary.
If it has the highest process ID, it sends a reply with an Election message.
If no Answer after 2s(this is arbitrary because Nun-db communication protocol is not synced), it became the leader and claims Victory, and send the Victory message
If P receives an Election message from another process with a lower ID, it sends an Answer message back. Then, it starts the election process at the beginning by sending an Election message to higher-numbered processes.
If P receives a Coordinator message, it treats the sender as the coordinator.
Here are the messages I would need to implement
Messages:
ElectionMessage node_id
Alive node_id
Victory -> SetPrimary
The only big problem I see in this implementation is the “no Answer after 1s” this may lead to several issues like no election will run in less than 1s, or if the latency between the servers is significant, then 1s may lead to miss behavior (but this will be a bigger problem already so I am less worried about that)
That happened because the algorithm assumes the communication is synchronous. Nun-db communication is not. That is why I decided to do that simple modification to keep the simplicity and not need to implement a request-response system dedicated only to the election. It is easy to change in the future if it turns out to be a problem.
At that point, I have a good understanding of what I wanted and all algorithms I would like to implement. Then, it was time to implement it and see how it would go.
Implementation
Where should I place the election code?
I decided there would be too many details on this to add it as part of other modules, so I added the election_ops module for that proposal.
The next diagram clarifies that election_ops sits behind the parser, so it does not deal with external interaction directly. Having the parser in the front makes it possible to use text-based messages and the already existent connections(TCP, for example) to send and receive the election messages that would be tread as just another request. This will simplify the implementation a lot.

Now let’s see at what points we should trigger the elections.
On the startup
The simple case is when a node start and the cluster is already running. In the startup of Nun-db, you can tell what replica sets it needs to connect, so in the beginning, it will ask to join all other servers to see if it is going al already running replica set; if so, no election needs to run it will join as secondary.
The code to join the replica set is simply easy. All it does is ask to join and disconnect and wait for the leader to come and connect back to it.
I think this code deserves some explanations. First, I wanted Nun-db to be able to start alone and not need any external process to manage how the replicate connects. On Nun-db startup, you need to tell what other replicas it needs to connect to, for example.
In the example above, we defined three replicas that are 127.0.0.1:3017 for the current process 127.0.0.1:3016 and 127.0.0.1:3018 as the other replicas this process needs to connect.
If this process is the first to start, the connections to **:3017 and **::3018 will fail, and the process will become the primary.
Secondary startup
With the idea to reduce the number of elections needed, this still a simple case, where any node joining an already running cluster will automatically be a secondary. So the only exciting part here may be to ask, why do I need to send a message to the replication thread start thread?
Nun-db will have an independent thread for each replica set connected to it (on primary or secondary), the replication_supervisor_sender works as more or less like a supervisor of the replication process, so if a replication thread dies, the replication_supervisor_sender will take care of cleaning up what needs to be clean up and it also responsible for starting and monitory new replication threads as well as keeping them running.
The process tells the already running cluster it is alive “asking” to join instead of connecting directly to the cluster, so we don’t make the supervisor thread busy early on in the startup process.
Now I think we are ready for the more complex case when the primary crashes.
The King is dead. Long live the King!
In the face of a crash, there is no other option other than electing a new leader. In Nun-db’s process, that means the next older process, so here is how it happens.
Who receives the message about the leader dying?
Every client connected to Nun-db is an instance of the structure Client, and every replica set is just another client with some special powers, which means that a replica set primary or secondary will have the field cluster_member as Some(Primary |
Secondary). |
With that, the thread holding the connecting to the replica can tell when the connection dies if that was a primary or a secondary. The replicas only use TCP connections to send and receive data. Therefore this code only needs to check for that in the tcp_ops(Checkout the diagram). The next block of code will show this process. You can also see it in code here, If it is, the primary disconnecting will send a leave message. If it is a secondary disconnecting will process a replicate-leave message, this is needed because secondaries leaving doesn’t require a new election to run. On the other hand, the primary will force an election.
Now to a better understanding of this function, we will need to create a scenario with three nodes so we can simulate the primary disconnecting and the other two secondaries debating for the new leadership role. Things will start to get complicated here, so let’s give our process names to make the story clear. We will start with a running cluster with three nodes, Emily, Sophia, and Yasmin (those are the name of my three beautiful nieces, so let’s call them the tree princesses) by age.
It all starts with:
- Primary -> Emily
- Secondary 1 -> Sophia
- Secondary 2 -> Yasmin
Emily disconnects (I will use disconnect instead of dying here for obvious reason)
1. All secondaries will be notified that the primary has disconnected.
1.1 Sophia will receive command left Emily 1.2 Yasmin will receive command left Emily
https://github.com/mateusfreira/nun-db/blob/d9902d58caa209b3b3769e24e421807a49ba0a70/src/lib/network/tcp_ops.rs#L69
https://github.com/mateusfreira/nun-db/blob/d9902d58caa209b3b3769e24e421807a49ba0a70/src/lib/process_request.rs#L211
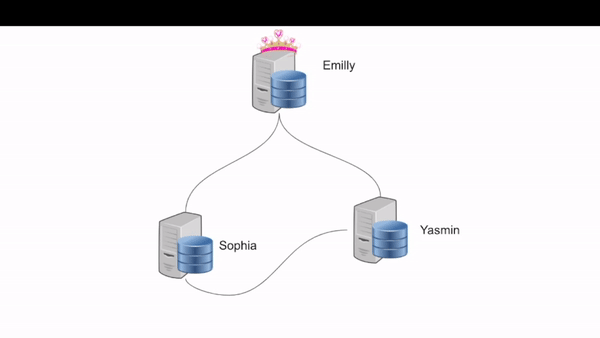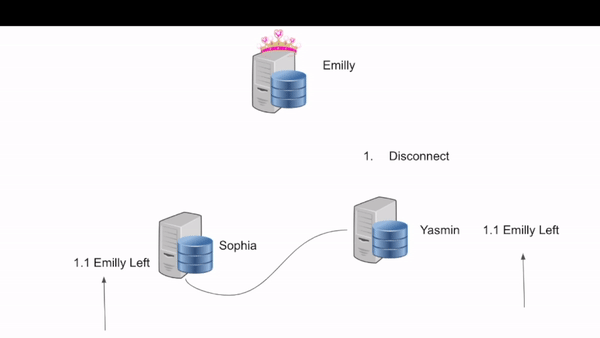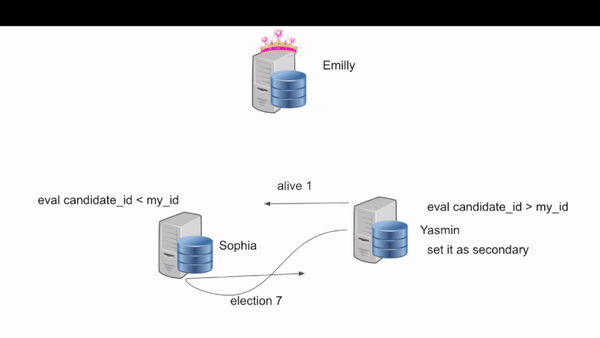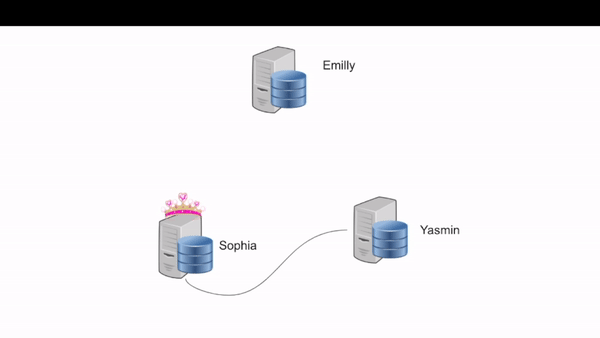
2. Each replicate will ask to start a new election
2.1 Sophia will set its role as Starting and send candidate 7 2.1 Yasmin will set its role as Starting and send candidate 1
https://github.com/mateusfreira/nun-db/blob/d9902d58caa209b3b3769e24e421807a49ba0a70/src/lib/election_ops.rs#L30
3. All of them receive the other message
3.1 Sophia receives the candidate one message from Yasmin and will send a candidate message back to Yasmin
3.2 Yasmin receives the candidate messages from Sophia and will send an election alive and set itself as secondary
https://github.com/mateusfreira/nun-db/blob/d9902d58caa209b3b3769e24e421807a49ba0a70/src/lib/process_request.rs#L166
3.3 Wait for 1s for the process to happen then.
https://github.com/mateusfreira/nun-db/blob/d9902d58caa209b3b3769e24e421807a49ba0a70/src/lib/bo.rs#L310
4. The leader claims to be the leader
4.1 Sophia claims to be the leader and sends the set-leader to Yasmin
4.2 Yasmin promote Sophia as her leader
The next GIF illustrates the same process but cuter!
That simple!!!!!
Conclusion
Leader election turned out to be a fun subject to research and implement, and now it is time to stress it in production and test it under mode chaotic situations. By the time I am writing this post, Nun-db has been running as a cluster for over two weeks, and no problem has been found(see Ps1). I have an upgrade needed to run from Linode. I think that will be a good experiment for the election on fire. I did test it a lot with fake failures, so I expect it will be fast and quick. The first election on production running will be a milestone I may want to share here soon.
One mistake I made was implementing the election directly in the Nun-db’s code base, instead of in a sandbox, in the data replication implementation I first implemented in a small code. It has given me a much better view of how it would look, and the final implementation was more straightforward. I started the election implementation before the replication, but I only consider it stable a week after the replication code was already merged and stable. On the other hand, the tests I created like the primary failing helped a lot on the stabilization and kept me sane during all the changes, so that was positive.
With leader election and replication working and stable, I want next to work on some atomic operations to Nun-db, to onboard some other new use cases, like $increment to increment keys value or $push to push data an array. It will depend on the new use cases I will be delivering next. For now, I will let the distributed feature run for like a month and keep monitoring the system to make sure it performs well as the applications using it grows on load. I also need to do a much better job on documentation and samples, so other devs can see better how to adopt Nun-db on some of their projects.
See you guys on the next step of this open-source journey!!
PSs
Ps1
There was one problem with this implementation, not in the election implementation but the replication algorithm. A Kubernetes node auto-update caused forcer primary reelection on Nun-db central deploy that triggered the problem. I noticed that all secondaries replicas, once they came back online, had full sync instead of partial quick sync, read the post for more details about the replication algorithm. That happened because the secondaries were not registering the oplog operation, which required a change to the replication strategy. As we use the replication infrastructure to process/send the election messages, we needed to add this, so we replicate notes if the node is is_primary() or is_eligible() because they are in the middle of an election, this is a potential change and does not change the election message flow.
Ps2
While I was proofreading this text, I listened to a great Changelog PodCast. Now I am more than convinced that we need to make Nun-db a multileader database for performance reasons. So, after working on the atomic operations and experimenting with the multi-node deployment on the Nun-db central cluster for a few months, I will be working on the multileader implementation. Raft may be the way to go here, but in the mean while I will be reading what is been published in distributed consensus to see if something new fits Nun-db core values.
References
-
- Diego Ongaro and John Ousterhout. 2014. In search of an understandable consensus algorithm. In Proceedings of the 2014 USENIX conference on USENIX Annual Technical Conference (USENIX ATC’14). USENIX Association, USA, 305–320.
-
- J. Villadangos, A. Cordoba, F. Farina, and M. Prieto, “Efficient leader election incomplete networks,” 13th Euromicro Conference on Parallel, Distributed and Network-Based Processing, 2005, pp. 136-143, DOI: 10.1109/EMPDP.2005.21.
-
- Coulouris, George; Dollimore, Jean; Kindberg, Tim (2000). Distributed Systems: Concepts and Design (3rd ed.). Addison Wesley.
-
- Kleppmann, M. (2017). Designing Data-Intensive Applications. Beijing: O’Reilly. ISBN: 978-1-4493-7332-0
- Code Coverage for Rust Projects with GitHub Actions
- NunDb is now referenced in the Database of Databases
- Real-time Medical Image Collaboration POC Made Easy with OHIF and Nun-db
- How to create users with different permission levels in Nun-db
- Match vs Hashmap! Which one is faster in rust?
- Towards a More Secure Nun-db: Our Latest Security Enhancements
- Building a Trello-like React/Redux App with NunDB with offline and conflict resolution features
- Introduction to managing conflicts in NunDB
- Keepin up with Nun-db 2023
- The new storage engine of Nun-db
- Stop procrastinating and just fix your flaky tests, it may be catching nasty bugs
- An approach to hunt and fix non-reproducible bugs - Case study - Fixing a race conditions in Nun-db replication algorithm in rust
- NunDB the debug command
- Keeping up with Nun-db 2021
- Writing a prometheus exporter in rust from idea to grafana chart
- Integration tests in rust a multi-process test example
- Leader election in rust the journey towards implementing nun-db leader election
- How to make redux TodoMVC example a real-time multiuser app with nun-db in 10 steps
- A fast-to-sync/search and space-optimized replication algorithm written in rust, The Nun-db data replication model
- NunDb How to backup one or all databases
- How to create your simple version of google analytics real-time using Nun-db
- Migrating a chat bot feature from Firebase to Nun-db
- Keepin' up with NunDB
- Going live with NunDB